
✦
前言
✦
本期分享的是北京邮电大学的王光宇研究团队于2025年发表在Nature Medicine上的论文:《A generalist medical language model for disease diagnosis assistance》。该研究提出了当前已知参数规模最大的开源医学语言模型 MedFound (176B),并在此基础上构建了通用医学诊断大语言模型MedFound-DX-PA。该模型展现出与临床专家相媲美的医学知识储备及诊断推理能力,能够为多种临床场景下的疾病诊断提供高效、准确的辅助支持。
论文地址
https://www.nature.com/articles/s41591-024-03416-6
代码地址
https://github.com/medfound/medfound
✦
研究背景
✦
在医疗保健领域中,提供准确的诊断至关重要,它是通往合理、及时治疗的关键入口。尽管医学从业者接受过系统且全面的培训,但诊断过程仍存在较高的误诊风险。已有研究数据表明,初级诊疗场景下的误诊率为 20%,这导致了约17% 的医疗不良事件。为提高诊断准确性,人们曾尝试采用规则化的临床决策支持系统(CDSS)以及基于机器学习算法的临床预测模型,但是此类方法通常依赖高度结构化的输入数据,且需操作者具备专业训练背景,因而存在流程复杂、资源消耗较大等问题。
近年来,预训练语言模型(PLM)尤其是大语言模型(LLM)的出现,极大推动了自然语言处理(NLP)领域的发展,为解决医疗预测分析的 “最后一公里” 挑战提供了可能。然而,当前LLM在生物医学领域的应用仍处于初步阶段,多数研究聚焦于LLM在医学领域的应用案例报告上,尚缺乏专为真实临床场景设计且可公开获取的模型。即便有少量研究尝试将临床知识融入LLM,用于医疗问答或对话等任务,但其在临床诊断推理方面的能力仍未得到充分开发与检验。更关键的是,生成式 LLM 存在幻觉和捏造事实的问题,其诊断建议可能会引发医疗风险。
为此,研究团队精心构建了一个涵盖广泛医学知识与临床经验的大规模语料库,其整合了庞大的中英文医学文献、专业书籍,以及来自真实世界的电子病历记录。基于该语料库,研究采用“预训练 - 微调 - 偏好对齐” 三阶段训练流程,使 LLM 具备接近医疗专家的知识及推理能力。此外,研究团队还引入了名为 CLEVER 的人类评估框架,该框架包含病历理解、风险管理等八个临床评估指标,验证了模型在现实世界医疗场景中的潜力。
✦
研究方法
✦
1.
预训练阶段
2.
第一阶段,研究团队构建了规模达63亿文本tokens的大型医疗语料库 MedCorpus,随后以此为支撑对通用领域大模型 BLOOM-176B 开展专项预训练,最终得到具备扎实医学知识储备的基础模型 MedFound。
MedCorpus 由 MedText、PMC-CR、MIMIC-III-Note 及 MedDX-Note 四个子数据集共同构成(图1)。其中,MedText 涵盖入门至高级水平的医学教科书、课堂讲稿及各类教育材料,覆盖肺科、泌尿科、精神病学、护理学、解剖学、血液学等多个领域,为模型搭建起多学科的医学知识框架;PubMed Central(PMC)收录了生物医学领域的大量研究文章,研究者将PMC中的病例报告整合为PMC-CR数据集,用于提升模型对各类疾病的认知与处理能力;MIMIC-III-Note 和 MedDX-Note 源自真实的临床数据,前者来自美国重症监护数据库,后者来自中国疾病诊断研究会。此类训练数据是增强模型医疗记录解读与分析能力的核心资源,助力模型把握真实医疗场景中的诊疗逻辑。
为保障训练数据质量,研究人员对 MedCorpus 进行了针对性数据预处理,包括移除文本中的特殊标签和无关冗余字符,并对文本进行分词处理。
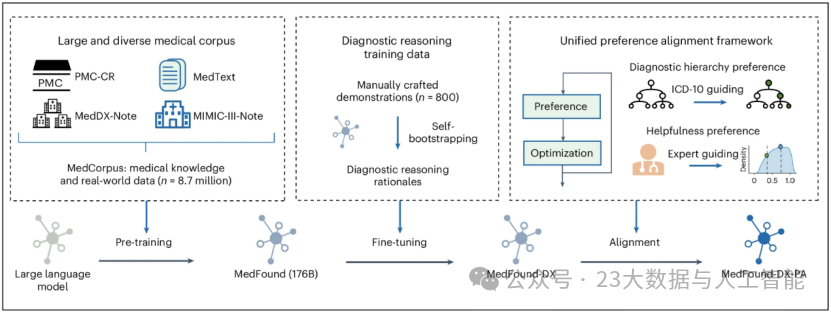
图1 MedFound的预训练,微调和偏好对齐流程
2. 微调阶段
第二阶段,研究团队采用自学推理(Self-Taught Reasoner, STaR)的方法构建思维链(Chain-of-Thought, CoT)数据集用于MedFound微调,数据集包含医疗记录和相关的诊断原理演示。
如图2所示,研究者首先构建了包含 800 条人工标注诊断推理示例的小规模数据集D0,这些示例均由专业医生针对特定病例撰写,详细拆解了诊断过程中的推理步骤;随后,研究者以这 800 条初始标注数据为训练样本,对预训练模型 MedFound 开展微调,得到具备初步诊断推理能力的模型 M'。
基于模型M',研究者对109364条未标注的EHR数据进行处理:先令 M' 为每条 EHR 分别生成推理路径 r1 与诊断结果 y1 ,随后针对同一条 EHR,以其对应的真实诊断结果 y 为引导提示(hint),再次调用 M' 生成推理路径 r2 。在推理路径筛选环节,若 M' 初始生成的诊断结果 y1 与真实诊断 y 一致,则保留初始推理路径 r1 ;若 y1 与 y 存在偏差,则用“以正确诊断 y 为提示生成的推理路径 r2 ”替换 r1 ,最终整合形成思维链数据集 D1={(xi, ri, yi)} 。其中 xi 为患者信息,ri 为经筛选确定的有效推理路径,yi 为临床确认的诊断结果。
最后,研究者将D1与D0整合为增强型数据集D2;再用该D2对基础模型MedFound开展微调,最终得到诊断准确性与可靠性更优的模型 M''。
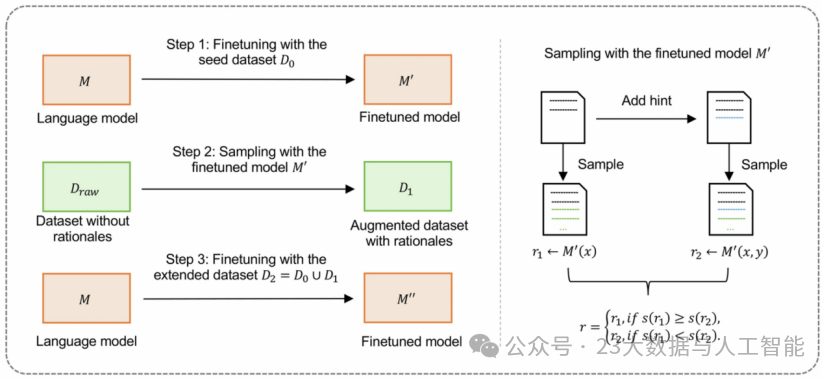
图2 MedFound的思维链微调过程
3. 偏好对齐阶段
第三阶段,研究者通过构建统一偏好对齐(PA)框架,该框架集成了诊断层级与帮助性两种偏好,并通过DPO算法对微调得到的MedFound-DX进一步优化,最终构建诊断性能更佳的MedFound-DX-PA。
诊断层次偏好以《国际疾病分类第十版》(ICD-10)的疾病分类树层级结构为指导,目标是令模型输出的诊断结果在疾病分类精度上与临床真实诊断高度匹配。以糖尿病相关诊断为例,模型需优先区分1型糖尿病、2 型糖尿病等细分类型,而非仅笼统归类为糖尿病。在图3中,橙色节点表示真实诊断结果对应的ICD编码,而蓝色与绿色节点分别代表模型输出的两个预测结果对应的ICD编码。根据诊断层次偏好标准,蓝色与橙色的公共父节点层级更深,模型对蓝色节点的预测结果应表现出更强的偏好性。
帮助性偏好的核心是避免输出模糊、错误或无临床意义的内容。研究者从模型输出结果中筛选出1800条诊断理由,邀请临床专家依据 “是否包含关键临床证据、推理逻辑是否连贯” 将其标注为“有帮助”或“无帮助”。 基于此标注数据集,研究者训练了二分类模型,以模型输出“有帮助”类别的预测概率p作为帮助性的评估指标。以图3为例,蓝色节点对应的诊断理由的“有用”概率高于绿色节点,根据帮助性偏好标准,模型应优先选择蓝色节点对应的诊断理由,以确保输出贴合临床实际需求。
✦
研究结果
✦
1、模型诊断性能基准测试
研究团队构建了 MedDX-Bench,这是一个由MedDX-Test、MedDX-OOD和 MedDX-Rare三个临床数据集组成的基准,旨在全面评估LLM在真实临床环境中的诊断能力。其中,MedDX-Test与训练数据集同分布且互斥,用于评估模型在已知疾病分布下的跨专业诊断性能。MedDX-OOD的地理分布、诊疗流程与训练集存在差异,可评估模型在分布外场景下的诊断泛化能力。MedDX-Rare为罕见病评估数据集,专门用于测试模型对低频、罕见疾病的诊断能力。
图4 MedFound的诊断性能基准测试
研究团队将MedFound-DX-PA与多个前沿大语言模型进行了比较,包括开源模型 MEDITRON-70B、Clinical Camel-70B、Llama 3-70B 以及商业闭源模型 GPT-4o。实验结果显示,在呼吸科、消化科、泌尿科、心血管科、免疫科、精神科、神经科、内分泌科八大学科领域,MedFound-DX-PA的Top-3 准确率均表现最佳,证明了该模型的强泛化能力和高精度诊断适应性。
2、 模型与医生之间的表现比较
在“AI与医生的对比研究”中,研究团队招募了18名医师,包括9名内分泌科和9名呼吸科医师,并按临床经验将其划分为初级、中级和高级三个组别(每组各3人),每位医师独立完成150例诊断任务。结果显示,MedFound-DX-PA 在这两个专科中不仅优于初级和中级医师,其诊断能力还可与高级医师相媲美。同时,实验也证明了模型在提升医生诊断能力方面的潜在作用。
3、 模型诊断能力的人工评估框架
此前针对医疗LLM的评估指标,多聚焦于准确性或自然语言生成分数(例如 BLEU、ROUGE)上,这些指标难以捕捉诊断推理过程的临床质量。为解决此问题,研究团队建立了一套系统化的的临床评估框架CLEVER,将 LLM 诊断系统的核心能力拆解为八个关键临床评估指标。评估实施阶段,研究者招募了6名高级医师,采用1-5分李克特量表对LLM的输出进行打分,并表明经过偏好对齐的 MedFound-DX-PA在核心指标上均显著优于未对齐模型。这些结果充分显示,LLM 医疗诊断系统可通过与人类价值观及临床规范的对齐实现优化,进而显著提升其诊断过程的可信度与实际临床适用性。
✦
研究总结
✦
本文提出了一款名为MedFound-DX-PA的医疗诊断专用大语言模型,通过大规模医学文本与真实临床记录进行预训练,并采用自举式思维链微调策略学习医师诊断推理过程,结合基于ICD-10层级结构与专家标注的统一偏好对齐框架,显著提升了模型在常见病、分布外泛化及罕见病诊断任务中的性能。该模型在八大学科领域中均优于现有基线模型与专用系统,并通过与医师对比研究、AI辅助诊断实验及CLEVER人类评估框架验证了其在实际临床工作流程中的有效性与安全性,为AI辅助诊断提供了可靠且可解释的通用解决方案。



