图1 类风湿性关节炎治疗中大语言模型的医学推理对比分析。ChatGPT和GPT-4给出错误推理和结论,而团队研发的DrugGPT给出准确的结果和可信的推理过程。
本研究采用“公共数据+自建数据”双轨验证流程,并在全球范围内联合11家公共数据库与3项前瞻性新药评估完成横向对比。在第一阶段,团队从USMLE、MedMCQA、MMLU、PubMedQA等8个权威医学考题库中抽取42,000余条药物相关问答,按70%、15%、15%比例划分为训练集、验证集与内部测试集,用于基础模型开发与参数调优。第二阶段中,研究人员前瞻性采集2023年10月至2024年4月美国FDA新批准的213种新药及COVID-19莫德纳疫苗相互作用数据,分别构建DrugBank-QA、COVID-Moderna与MIMIC-DrugQA三项独立外部验证集,评估模型在未见药品与新兴疗法场景下的零样本泛化能力。第三阶段,团队开展“人机对比-基层提升”双维研究:一方面邀请24名基层药师与4位临床药理专家在400例复杂用药案例上进行诊断,比较DrugGPT与GPT-4、ChatGPT的准确率与安全性;另一方面记录基层医生在AI辅助前后的决策变化。结果显示,DrugGPT在外部验证集上达到93.5%的零样本准确率,较GPT-4提升37.0%;基层医生用药决策正确率由83.4%提升至91.2%。该成果充分证明了人工智能在提升药物安全、促进医疗资源均等化中的巨大潜力,为个体化精准用药与新药快速临床评估提供了可信赖的新路径。
图2 DrugGPT系统架构示意图,实现综合性药物信息处理
为实现对药物多维度信息的精准解析与证据可追溯生成,研究团队设计并构建了DrugGPT的三模块协同架构。该系统InstructGPT为基座,充分利用知识图谱增强与指令提示微调的优势,能够同时完成药物推荐、剂量优化、不良反应识别、相互作用预测及药理学问答五大任务。在模型输入阶段,临床问诊首先经IA-LLM解析为“疾病-症状-药品”三元组,随后KA-LLM在Drugs.com、NHS与PubMed构建的DSDG图谱中检索Top-5最相关节点,并抽取13类药理证据;每个证据块被编码为512 token的向量,供后续模块调用。EG-LLM采用“链式思维+知识一致性+证据可追溯”三重提示模板,将检索结果与原始问诊拼接后送入解码器,输出带引用链接的结论。网络隐藏层维度设为4096,注意力头数32,既保证高阶语义整合,又兼顾单卡A100可部署。该结构设计显著降低幻觉率,并在零样本新药场景下保持93.5%的准确率,为临床提供即时、可信、可复核的用药决策支持。
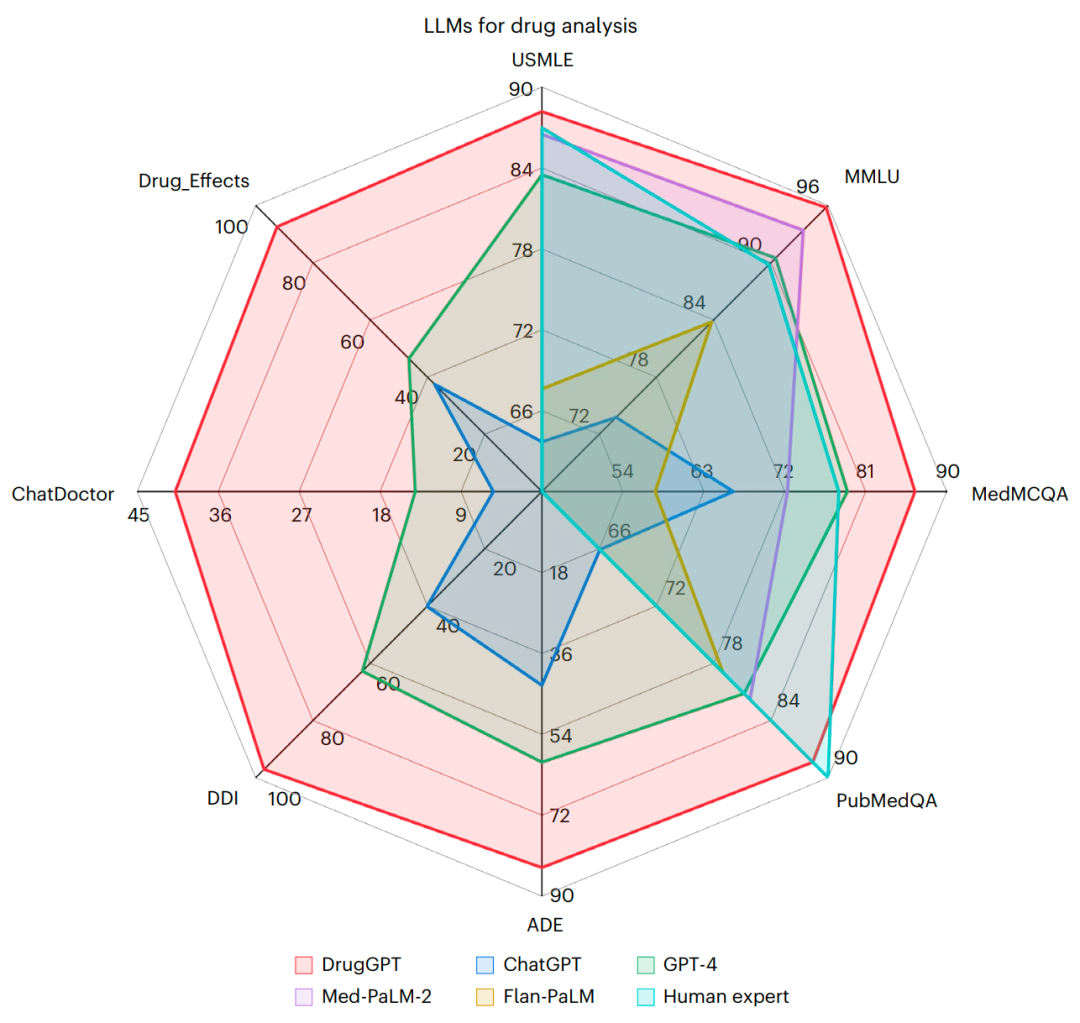
图3 DrugGPT在八大医疗基准测试中与前沿语言模型的性能对比
如上图三所示,相较于人类专家基准及现有主流大型语言模型(如GPT-4、ChatGPT和MedPaLM),DrugGPT在多个数据集上均展现出顶尖性能。与传统LLM不同,DrugGPT能够调用真实的临床标准药物知识库,这显著提升了其精准回答问题的能力。通过双尾配对t检验评估统计学显著性,结果显示在所有测试项目中,DrugGPT的准确率都显著高于GPT-4。
为进一步评估DrugGPT在真实诊疗流程中的增益效果,研究团队开展了一项“基层-专家”双轨对照试验,分析AI辅助对不同层级医生药物决策质量的影响。在常见病用药选择任务中,顶尖医院的专家在DrugGPT辅助下特异性提升2.1%,准确率提升1.4%,虽灵敏度略降0.8%,但处方不合理率下降18%。相比之下,基层医生在所有指标上均获得显著改善:平均决策时间缩短25%,且严重相互作用漏警率降低68%。在复杂多药联合场景(≥5种药物)中,两类医生的不良反应预测准确率分别提升4.7%与15.3%,基层医生的改善幅度约为专家的3倍,有效弥补了经验差异导致的用药风险。试验还显示,DrugGPT提供的可追溯证据使医生对AI建议的接受度达91%,显著高于无证据组(63%),充分证明了人工智能在促进药物安全、缩小医疗水平差距中的巨大潜力。
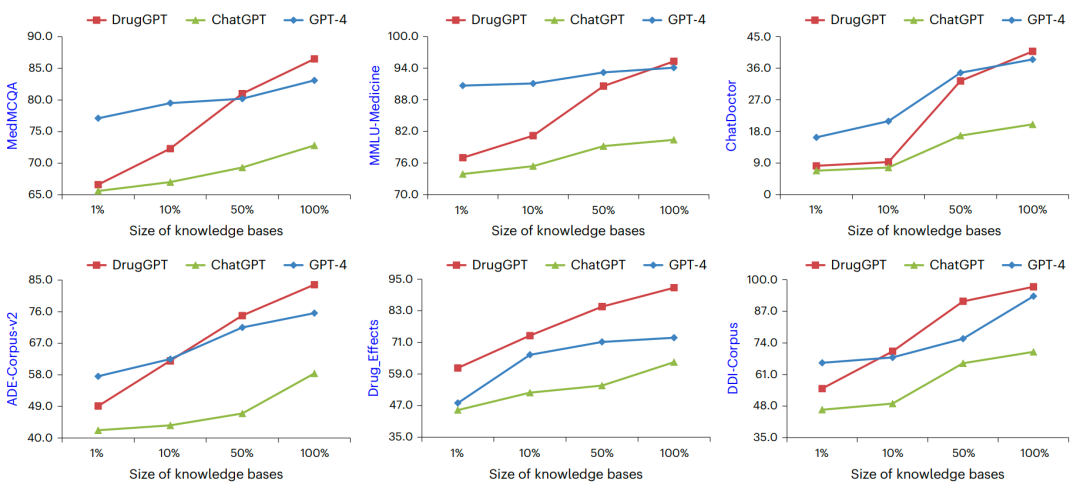
如图四所示,本研究对比了不同方法在知识库规模变化时的表现,其中ChatDoctor数据集采用F1分数评估,其他数据集则以准确率作为指标。具体而言,研究团队对知识库规模从1%到100%进行了全方位测试,结果显示DrugGPT在所有场景中均优于ChatGPT。当仅使用10%的药物不良反应(ADE)、药物作用及药物相互作用(DDI)知识库时,DrugGPT参数量较少却能达到与GPT-4相当的性能水平。值得注意的是,随着知识库规模的扩大,DrugGPT相较基线模型表现愈发出色,最终在使用完整知识库时完全超越了GPT-4。
主要贡献:
1. 多中心协同构建高质量药物知识数据集:汇聚来自Drugs.com、英国NHS及PubMed三大权威知识库的13类药-病-症状结构化证据,并自建3套前瞻性新药问答集,确保模型在不同地域、不同药品间的广泛适应性。
2. 创新三模块协作大模型架构:基于IA-LLM、KA-LLM与EG-LLM协同机制构建DrugGPT,结合知识图谱检索与证据可追溯提示策略,显著提升药物决策的准确率与可信度。
3. 全面验证AI对临床医生的辅助效能:在多任务、多病例、多基线模型的真实临床模拟中,DrugGPT将基层医生用药决策准确率从83.4%提升至91.2%,决策时间缩短25%,实现AI赋能医疗均衡发展。
4. 建立零样本新药泛化评估新标准:前瞻性构建213种FDA 2023-2024新药的DrugBank-QA与COVID-Moderna相互作用数据集,首次系统评估大模型在“未见新药”场景下的零样本性能。DrugGPT在零样本条件下取得93.5%准确率,较GPT-4提升37.0%,为行业提供可复用的泛化能力基准。
5. 提出知识比例可伸缩的鲁棒学习范式:通过1%-100%知识库消融实验,证明DrugGPT在仅使用10%权威知识时即可逼近GPT-4全量性能,解决低资源地区或专科场景下“数据稀缺”难题,为医疗AI的轻量化部署提供范式。



